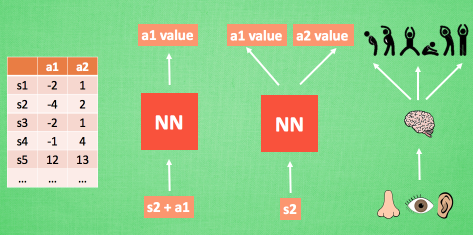
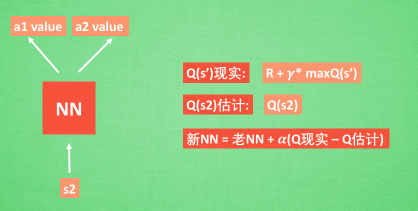
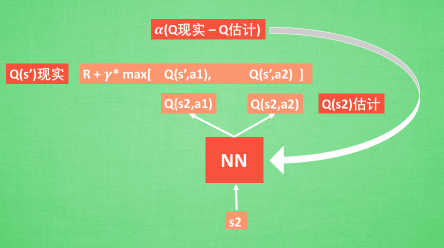
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
75
76
77
78
79
80
81
82
83
84
85
86
87
88
89
90
91
92
93
94
95
96
97
98
99
100
101
102
103
104
105
106
107
108
109
110
111
112
113
114
115
116
117
118
119
120
121
122
123
124
125
126
127
128
129
130
131
132
133
134
135
136
137
138
139
140
141
142
143
144
145
146
147
148
149
150
151
152
153
154
155
156
157
158
159
| """
This part of code is the Q learning brain, which is a brain of the agent.
All decisions are made in here.
View more on my tutorial page: https://morvanzhou.github.io/tutorials/
Pytorch: https://github.com/ClownW/Reinforcement-learning-with-PyTorch
Tensorflow: https://github.com/MorvanZhou/Reinforcement-learning-with-tensorflow
"""
import numpy as np
import tensorflow as tf
np.random.seed(1)
tf.set_random_seed(1)
class DeepQNetwork:
def __init__(
self,
n_actions,
n_features,
learning_rate=0.01,
reward_decay=0.9,
e_greedy=0.9,
replace_target_iter=300,
memory_size=500,
batch_size=32,
e_greedy_increment=None,
output_graph=False,
):
self.n_actions = n_actions
self.n_features = n_features
self.lr = learning_rate
self.gamma = reward_decay
self.epsilon_max = e_greedy
self.replace_target_iter = replace_target_iter
self.memory_size = memory_size
self.batch_size = batch_size
self.epsilon_increment = e_greedy_increment
self.epsilon = 0 if e_greedy_increment is not None else self.epsilon_max
self.learn_step_counter = 0
self.memory = np.zeros((self.memory_size, n_features * 2 + 2))
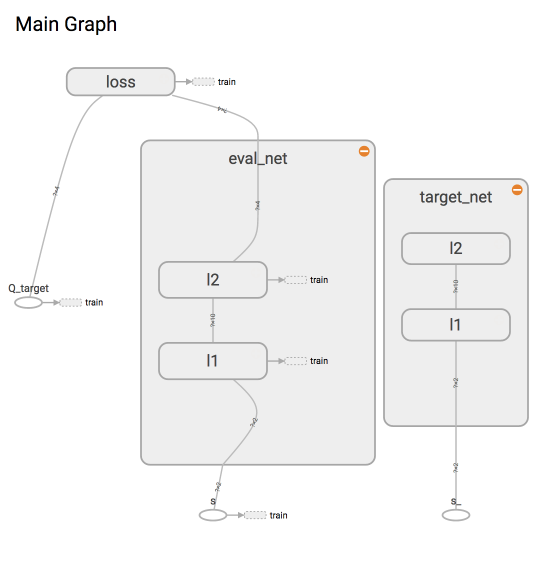
self._build_net()
t_params = tf.get_collection(tf.GraphKeys.GLOBAL_VARIABLES, scope='target_net')
e_params = tf.get_collection(tf.GraphKeys.GLOBAL_VARIABLES, scope='eval_net')
with tf.variable_scope('hard_replacement'):
self.target_replace_op = [tf.assign(t, e) for t, e in zip(t_params, e_params)]
self.sess = tf.Session()
if output_graph:
tf.summary.FileWriter("logs/", self.sess.graph)
self.sess.run(tf.global_variables_initializer())
self.cost_his = []
def _build_net(self):
self.s = tf.placeholder(tf.float32, [None, self.n_features], name='s')
self.s_ = tf.placeholder(tf.float32, [None, self.n_features], name='s_')
self.r = tf.placeholder(tf.float32, [None, ], name='r')
self.a = tf.placeholder(tf.int32, [None, ], name='a')
w_initializer, b_initializer = tf.random_normal_initializer(0., 0.3), tf.constant_initializer(0.1)
with tf.variable_scope('eval_net'):
e1 = tf.layers.dense(self.s, 20, tf.nn.relu, kernel_initializer=w_initializer,
bias_initializer=b_initializer, name='e1')
self.q_eval = tf.layers.dense(e1, self.n_actions, kernel_initializer=w_initializer,
bias_initializer=b_initializer, name='q')
with tf.variable_scope('target_net'):
t1 = tf.layers.dense(self.s_, 20, tf.nn.relu, kernel_initializer=w_initializer,
bias_initializer=b_initializer, name='t1')
self.q_next = tf.layers.dense(t1, self.n_actions, kernel_initializer=w_initializer,
bias_initializer=b_initializer, name='t2')
with tf.variable_scope('q_target'):
q_target = self.r + self.gamma * tf.reduce_max(self.q_next, axis=1, name='Qmax_s_')
self.q_target = tf.stop_gradient(q_target)
with tf.variable_scope('q_eval'):
a_indices = tf.stack([tf.range(tf.shape(self.a)[0], dtype=tf.int32), self.a], axis=1)
self.q_eval_wrt_a = tf.gather_nd(params=self.q_eval, indices=a_indices)
with tf.variable_scope('loss'):
self.loss = tf.reduce_mean(tf.squared_difference(self.q_target, self.q_eval_wrt_a, name='TD_error'))
with tf.variable_scope('train'):
self._train_op = tf.train.RMSPropOptimizer(self.lr).minimize(self.loss)
def store_transition(self, s, a, r, s_):
if not hasattr(self, 'memory_counter'):
self.memory_counter = 0
transition = np.hstack((s, [a, r], s_))
index = self.memory_counter % self.memory_size
self.memory[index, :] = transition
self.memory_counter += 1
def choose_action(self, observation):
observation = observation[np.newaxis, :]
if np.random.uniform() < self.epsilon:
actions_value = self.sess.run(self.q_eval, feed_dict={self.s: observation})
action = np.argmax(actions_value)
else:
action = np.random.randint(0, self.n_actions)
return action
def learn(self):
if self.learn_step_counter % self.replace_target_iter == 0:
self.sess.run(self.target_replace_op)
print('\ntarget_params_replaced\n')
if self.memory_counter > self.memory_size:
sample_index = np.random.choice(self.memory_size, size=self.batch_size)
else:
sample_index = np.random.choice(self.memory_counter, size=self.batch_size)
batch_memory = self.memory[sample_index, :]
_, cost = self.sess.run(
[self._train_op, self.loss],
feed_dict={
self.s: batch_memory[:, :self.n_features],
self.a: batch_memory[:, self.n_features],
self.r: batch_memory[:, self.n_features + 1],
self.s_: batch_memory[:, -self.n_features:],
})
self.cost_his.append(cost)
self.epsilon = self.epsilon + self.epsilon_increment if self.epsilon < self.epsilon_max else self.epsilon_max
self.learn_step_counter += 1
def plot_cost(self):
import matplotlib.pyplot as plt
plt.plot(np.arange(len(self.cost_his)), self.cost_his)
plt.ylabel('Cost')
plt.xlabel('training steps')
plt.show()
if __name__ == '__main__':
DQN = DeepQNetwork(3,4, output_graph=True)
|