1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
75
76
77
78
79
80
81
82
83
84
85
86
87
88
89
90
91
92
93
94
95
96
97
98
99
100
101
102
103
104
105
106
107
108
109
110
111
112
113
114
115
116
117
118
119
120
121
122
123
124
125
126
127
128
129
130
131
132
133
134
135
136
137
138
139
140
141
142
143
144
145
146
147
148
149
150
151
152
153
154
155
156
157
158
159
160
161
162
163
| """
A simple version of Proximal Policy Optimization (PPO) using single thread.
Based on:
1. Emergence of Locomotion Behaviours in Rich Environments (Google Deepmind): [https://arxiv.org/abs/1707.02286]
2. Proximal Policy Optimization Algorithms (OpenAI): [https://arxiv.org/abs/1707.06347]
View more on my tutorial website: https://morvanzhou.github.io/tutorials
Dependencies:
tensorflow r1.2
gym 0.9.2
"""
import tensorflow as tf
import numpy as np
import matplotlib.pyplot as plt
import gym
EP_MAX = 1000
EP_LEN = 200
GAMMA = 0.9
A_LR = 0.0001
C_LR = 0.0002
BATCH = 32
A_UPDATE_STEPS = 10
C_UPDATE_STEPS = 10
S_DIM, A_DIM = 3, 1
METHOD = [
dict(name='kl_pen', kl_target=0.01, lam=0.5),
dict(name='clip', epsilon=0.2),
][1]
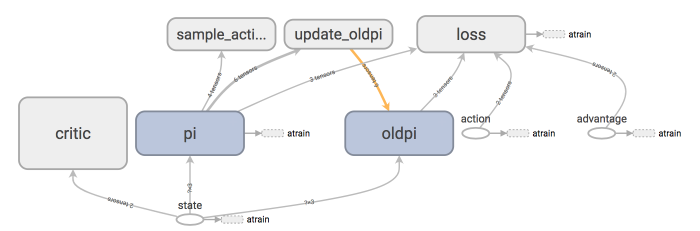
class PPO(object):
def __init__(self):
self.sess = tf.Session()
self.tfs = tf.placeholder(tf.float32, [None, S_DIM], 'state')
with tf.variable_scope('critic'):
l1 = tf.layers.dense(self.tfs, 100, tf.nn.relu)
self.v = tf.layers.dense(l1, 1)
self.tfdc_r = tf.placeholder(tf.float32, [None, 1], 'discounted_r')
self.advantage = self.tfdc_r - self.v
self.closs = tf.reduce_mean(tf.square(self.advantage))
self.ctrain_op = tf.train.AdamOptimizer(C_LR).minimize(self.closs)
pi, pi_params = self._build_anet('pi', trainable=True)
oldpi, oldpi_params = self._build_anet('oldpi', trainable=False)
with tf.variable_scope('sample_action'):
self.sample_op = tf.squeeze(pi.sample(1), axis=0)
with tf.variable_scope('update_oldpi'):
self.update_oldpi_op = [oldp.assign(p) for p, oldp in zip(pi_params, oldpi_params)]
self.tfa = tf.placeholder(tf.float32, [None, A_DIM], 'action')
self.tfadv = tf.placeholder(tf.float32, [None, 1], 'advantage')
with tf.variable_scope('loss'):
with tf.variable_scope('surrogate'):
ratio = pi.prob(self.tfa) / (oldpi.prob(self.tfa) + 1e-5)
surr = ratio * self.tfadv
if METHOD['name'] == 'kl_pen':
self.tflam = tf.placeholder(tf.float32, None, 'lambda')
kl = tf.distributions.kl_divergence(oldpi, pi)
self.kl_mean = tf.reduce_mean(kl)
self.aloss = -(tf.reduce_mean(surr - self.tflam * kl))
else:
self.aloss = -tf.reduce_mean(tf.minimum(
surr,
tf.clip_by_value(ratio, 1.-METHOD['epsilon'], 1.+METHOD['epsilon'])*self.tfadv))
with tf.variable_scope('atrain'):
self.atrain_op = tf.train.AdamOptimizer(A_LR).minimize(self.aloss)
tf.summary.FileWriter("log/", self.sess.graph)
self.sess.run(tf.global_variables_initializer())
def update(self, s, a, r):
self.sess.run(self.update_oldpi_op)
adv = self.sess.run(self.advantage, {self.tfs: s, self.tfdc_r: r})
if METHOD['name'] == 'kl_pen':
for _ in range(A_UPDATE_STEPS):
_, kl = self.sess.run(
[self.atrain_op, self.kl_mean],
{self.tfs: s, self.tfa: a, self.tfadv: adv, self.tflam: METHOD['lam']})
if kl > 4*METHOD['kl_target']:
break
if kl < METHOD['kl_target'] / 1.5:
METHOD['lam'] /= 2
elif kl > METHOD['kl_target'] * 1.5:
METHOD['lam'] *= 2
METHOD['lam'] = np.clip(METHOD['lam'], 1e-4, 10)
else:
[self.sess.run(self.atrain_op, {self.tfs: s, self.tfa: a, self.tfadv: adv}) for _ in range(A_UPDATE_STEPS)]
[self.sess.run(self.ctrain_op, {self.tfs: s, self.tfdc_r: r}) for _ in range(C_UPDATE_STEPS)]
def _build_anet(self, name, trainable):
with tf.variable_scope(name):
l1 = tf.layers.dense(self.tfs, 100, tf.nn.relu, trainable=trainable)
mu = 2 * tf.layers.dense(l1, A_DIM, tf.nn.tanh, trainable=trainable)
sigma = tf.layers.dense(l1, A_DIM, tf.nn.softplus, trainable=trainable)
norm_dist = tf.distributions.Normal(loc=mu, scale=sigma)
params = tf.get_collection(tf.GraphKeys.GLOBAL_VARIABLES, scope=name)
return norm_dist, params
def choose_action(self, s):
s = s[np.newaxis, :]
a = self.sess.run(self.sample_op, {self.tfs: s})[0]
return np.clip(a, -2, 2)
def get_v(self, s):
if s.ndim < 2: s = s[np.newaxis, :]
return self.sess.run(self.v, {self.tfs: s})[0, 0]
env = gym.make('Pendulum-v0').unwrapped
ppo = PPO()
all_ep_r = []
for ep in range(EP_MAX):
s = env.reset()
buffer_s, buffer_a, buffer_r = [], [], []
ep_r = 0
for t in range(EP_LEN):
env.render()
a = ppo.choose_action(s)
s_, r, done, _ = env.step(a)
buffer_s.append(s)
buffer_a.append(a)
buffer_r.append((r+8)/8)
s = s_
ep_r += r
if (t+1) % BATCH == 0 or t == EP_LEN-1:
v_s_ = ppo.get_v(s_)
discounted_r = []
for r in buffer_r[::-1]:
v_s_ = r + GAMMA * v_s_
discounted_r.append(v_s_)
discounted_r.reverse()
bs, ba, br = np.vstack(buffer_s), np.vstack(buffer_a), np.array(discounted_r)[:, np.newaxis]
buffer_s, buffer_a, buffer_r = [], [], []
ppo.update(bs, ba, br)
if ep == 0: all_ep_r.append(ep_r)
else: all_ep_r.append(all_ep_r[-1]*0.9 + ep_r*0.1)
print(
'Ep: %i' % ep,
"|Ep_r: %i" % ep_r,
("|Lam: %.4f" % METHOD['lam']) if METHOD['name'] == 'kl_pen' else '',
)
plt.plot(np.arange(len(all_ep_r)), all_ep_r)
plt.xlabel('Episode');plt.ylabel('Moving averaged episode reward');plt.show()
|